AI workbench for client data onboarding. Built for implementation teams at vertical SaaS.
Book WalkthroughNewsletter
Get the latest updates on product features and implementation best practices.
AI workbench for client data onboarding. Built for implementation teams at vertical SaaS.
Book WalkthroughNewsletter
Get the latest updates on product features and implementation best practices.

Poor data quality costs organizations an average of $12.9 million every year [1]. This staggering financial drain often originates from a single, overlooked source: the seemingly simple act of importing a CSV or Excel file. But the true cost isn't just financial. For skilled professionals, manual data cleaning is a significant drain on resources, consuming up to , time that could be dedicated to high-impact analysis and innovation [2].
This is the "data janitor" paradox: companies pay six-figure salaries for glorified data custodians instead of strategic analysts [3]. A single misplaced character, an assumed date format, or a hidden comma can derail entire projects, corrupt business intelligence, and grind operations to a halt. But which errors are the most common? Which ones cause the most damage?
Based on a systematic review of hundreds of discussions across professional communities like Stack Overflow and Reddit, we've compiled a definitive, quantitative analysis of the top 11 data import errors. This is the anatomy of a failed import, a deep dive into the silent killers of data productivity.
The Problem: This is the quintessential, destructive Excel error. When a file containing numeric identifiers (ZIP codes, product IDs, phone numbers, GL codes) is opened, Excel’s default "General" format automatically interprets them as mathematical numbers. This triggers two critical and destructive failures:
02134 becomes 2134) [4].1.2408E+12 due to a 15-digit precision limit) [5].Once the file is saved, this data loss is permanent and irreversible.
Business Impact: Catastrophic. The loss of a single character in a unique identifier renders it useless for record matching, VLOOKUPs, or database joins [6]. This single error can paralyze shipping operations, corrupt inventory management, and break financial reconciliation. As one user on Reddit lamented, "The leading zeros are part of a parcel numbers... I'm importing as a CSV direct from the source of the data." [4]. The data is silently corrupted before the import process even begins.
The Manual Workaround: A reactive loop of pain. Users are forced to pre-format columns as 'Text' before opening a file, use Excel formulas like TEXT(), or manually add a leading apostrophe (') to every single cell to force a text format [5, 4]. This is the kind of low-value task that contributes to the "80/20 rule," where skilled analysts spend their days on manual fixes instead of analysis [2].
The Automated Solution: Instantly preserve data integrity by defining column types in the transformation. A modern data transformation tool like DataFlowMapper treats all data as text by default, ensuring that critical identifiers like 02134 are never corrupted. No manual workarounds, no data loss. See our guide on how to preserve leading 0's here.
The Problem: Dates are a classic source of chaos because there is no single, universal format. An import system expecting YYYY-MM-DD that receives MM/DD/YYYY or DD/MM/YYYY will either fail or, worse, silently misinterpret the data [7, 8]. The date 05/04/2024 could be May 4th or April 5th. One user expressed the frustration perfectly: "It changes automatically. Some of them. I want it to be uniform." [9].
Business Impact: Severe. Misinterpreted dates lead to incorrect financial reporting, broken logistics schedules, misaligned employee records, and failed audits [10]. It's a subtle error with massive downstream consequences.
The Manual Workaround: This involves painful, manual processes like using Excel's "Text to Columns" feature to re-parse dates or applying complex, nested DATEVALUE() and TEXT() formulas that are difficult to audit and maintain [11].
The Automated Solution: Eliminate date chaos with a powerful, purpose-built function library. Instead of brittle formulas, DataFlowMapper's visual Logic Builder lets you apply a formatDate function to an entire column, instantly standardizing thousands of inconsistent dates into a single, unambiguous format like YYYY-MM-DD.
The Problem: The foundational rule of the CSV format is that commas serve as delimiters. When a data field itself contains a comma (e.g., "Boston, MA"), it must be enclosed in double quotes [12]. If not, the parser sees an extra delimiter and breaks the file's structure, shifting all subsequent data in that row into the wrong columns. The same issue occurs when a quote character exists within the data itself without being properly escaped [13].
Business Impact: Critical data misalignment and structural failure. This is how a customer's city ends up in the postal code field, or a last name is imported as an email address. A user on Stack Overflow explained, "The Reason was that sometimes column contains Comma (,) that is used as column delimiter so the Row are not imported Correctly." [13].
The Manual Workaround: Manually opening the file in a text editor to find and enclose the offending fields in quotes, a nearly impossible and soul-destroying task for files with thousands of rows [14].
The Automated Solution: A robust parsing engine should handle this automatically. DataFlowMapper's intelligent parser correctly interprets standard CSV quoting and escaping rules (RFC 4180), ensuring your data's structural integrity without any manual intervention.
The Problem: The "C" in CSV is often a lie. Files can be delimited by semicolons (common in Europe), tabs, or pipes [12]. If an import tool is hard-coded to only accept commas, it will fail to parse the file, often collapsing all data into a single, unusable column [19].
Business Impact: A hard-stop import failure. The data is completely inaccessible until the format is corrected, causing significant delays in data onboarding, migrations, and analysis. This is a frequent point of friction when receiving data from clients [20].
The Manual Workaround: Opening the raw file in a text editor to identify the delimiter, then using a spreadsheet's "Text Import Wizard" or a manual Find and Replace operation to standardize it before attempting the import again [21, 22].
The Automated Solution: Never let the wrong delimiter stop you. DataFlowMapper allows you to specify the delimiter (comma, semicolon, tab, pipe, etc.) when you upload your source file, instantly parsing the data correctly regardless of its format.
The Problem: Real-world data is messy and incomplete. Required fields are often blank [7]. An import system may either reject the row entirely or ambiguously handle the empty cell, converting it to a 0, NULL, or an empty string. This ambiguity can break downstream calculations and business logic [23].
Business Impact: Incomplete records and inaccurate analysis. A missing email address can prevent a customer record from being created [20]. A NULL value for "quantity" that becomes 0 can drastically skew financial reports and inventory forecasts [23].
The Manual Workaround: Manually finding and filling in missing data, or using complex IF(ISBLANK(...)) formulas to convert blank cells to a desired default format [24]. This is tedious work that keeps professionals from their "actual thinking" [25].
The Automated Solution: Turn messy data into clean data with a two-pronged approach. First, use DataFlowMapper's validation engine to instantly flag all rows with missing required fields. Then, use the visual Logic Builder with a function like is_blank to conditionally replace NULL values with a specific default (like "N/A" or 0), giving you complete, auditable control over data quality.
The Problem: An Excel file is imported containing dynamic formulas (=VLOOKUP(...), =SUM(A1:A5)) instead of static values. The target system, expecting a simple value, either fails the import or incorrectly loads the formula string itself [15, 26].
Business Impact: The data is either rejected or imported incorrectly, making it useless for reporting or analysis. A report that should show $500.00 instead shows the text =A1+B1 [26].
The Manual Workaround: The tedious, multi-step process of using Excel's "Copy > Paste Special > Values" to flatten the data and remove its dynamic nature before import [27]. This creates a disconnected, static copy of the data that is prone to versioning errors.
The Automated Solution: Work with the results, not the recipes. When you upload an Excel file to DataFlowMapper, it reads the displayed, calculated values, not the underlying formulas, ensuring that the correct, static data is used in your transformations every time.
The Problem: A supposedly structured file has rows with different numbers of columns [12]. This is almost always a symptom of another root-cause error, such as an unescaped comma or a missing delimiter [28].
Business Impact: A hard-stop import failure. The parser cannot continue once the file's structure is broken, preventing the entire file from being loaded and leaving the user to hunt for the single offending row.
The Manual Workaround: Manually scanning the raw text file to find and fix the offending rows, a frustrating and highly error-prone task that is simply not feasible for large datasets [22].
The Automated Solution: Solve the root cause, not the symptom. This error disappears automatically when you use a robust parsing engine that correctly handles quoting and delimiters.
The Problem: The header row is missing, the column names don't match the required template for the target system (e.g., 'First Name' vs 'FNAME'), or there are duplicate headers [12, 29].
Business Impact: The import system cannot map the incoming data to the correct fields in the target database. This is a foundational error that leads to miscategorized data or complete import failure. It's a primary source of friction in client data onboarding [26].
The Manual Workaround: Manually editing the header row in Excel to perfectly match the required template, a task ripe for typos and errors.
The Automated Solution: Make mapping intuitive and error-free. DataFlowMapper's visual interface displays your source and destination headers side-by-side. You can instantly see which fields don't match and visually drag-and-drop to create the correct mapping, or use AI-powered "Suggest Mappings" to analyze both schemas and propose the complete mapping for you.
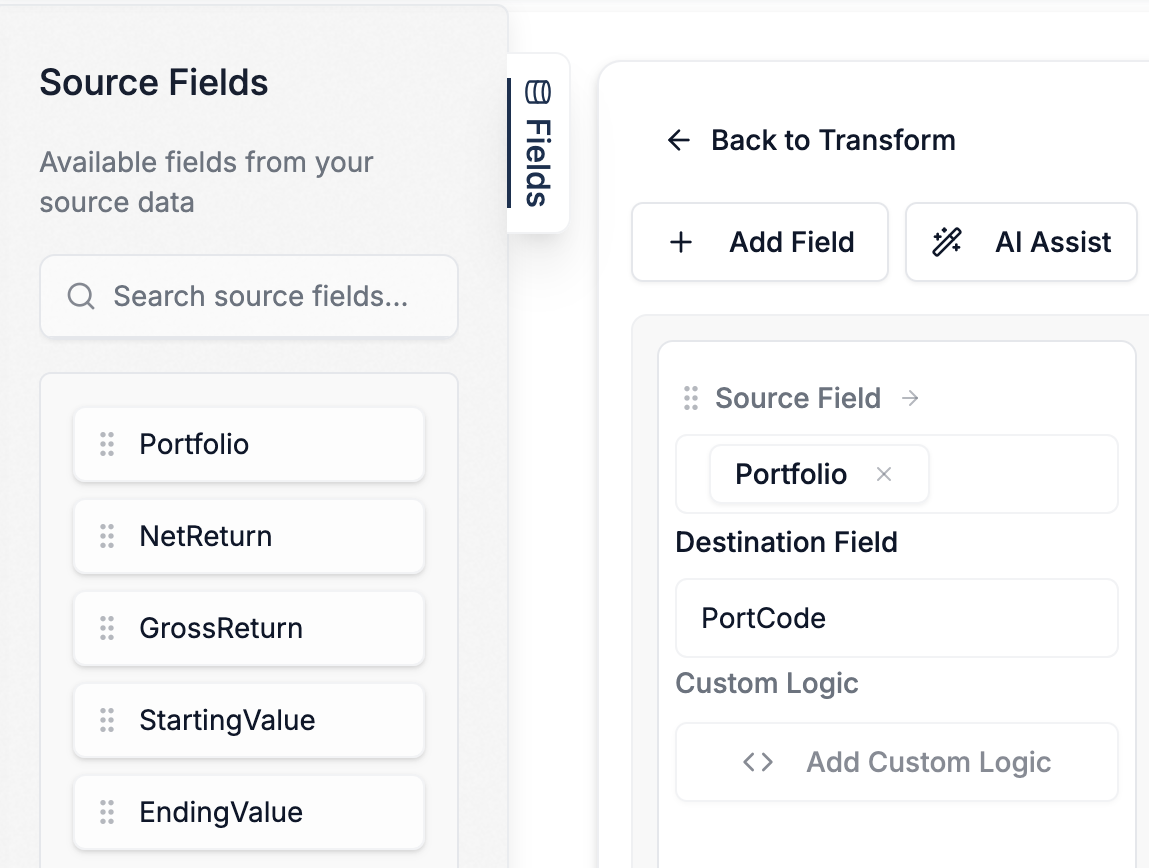
The Problem: Invisible characters (leading/trailing spaces, or non-breaking spaces copied from the web) are present in the data [26]. The data looks clean, but these hidden characters cause validation, lookups, and record matching to fail. As one user lamented, "I just have no idea how non-breaking spaces got into the document. But at least it explains why I wasn't able to see anything wrong." [30].
Business Impact: Infuriating, time-consuming troubleshooting. Users spend hours trying to diagnose a problem they cannot see, leading to failed imports and broken VLOOKUPs that "should" work [31].
The Manual Workaround: Applying Excel's TRIM() and CLEAN() functions to every relevant column, hoping it catches all variations of hidden characters [26].
The Automated Solution: Instantly rescue your data from invisible errors with a one-click operation. In DataFlowMapper's Logic Builder, you can apply a whitespace-cleaning function to a column to strip all leading and trailing spaces from thousands of rows as part of a repeatable recipe.
The Problem: The source file is too large for the import tool to handle, either due to row limits (like in Excel and Google Sheets) or memory constraints of a web-based application, causing it to crash or freeze [15, 12].
Business Impact: A significant bottleneck for businesses with large datasets. The user is prevented from ingesting their data, forcing them into inefficient and risky workarounds.
The Manual Workaround: Manually splitting the large file into multiple smaller files, a time-consuming process that can easily introduce new errors, data duplication, or omissions [7].
The Automated Solution: Process data at scale without compromise. DataFlowMapper is designed with a streaming architecture to handle large files efficiently, processing millions of rows without crashing your browser, eliminating the need for manual file splitting.
The Problem: The data in a column doesn't match the expected data type of the target field (e.g., text in a numbers-only column, or "Yes" in a boolean field that expects TRUE or 1) [15].
Business Impact: Row-level import failures or, worse, the import of bad data that corrupts reporting and analytics downstream. A simple typo can cause a critical record to be rejected, requiring manual investigation [32].
The Manual Workaround: Manually finding and correcting the offending cells, or using formulas like VALUE() to convert data types one column at a time [33].
The Automated Solution: Enforce data quality with powerful validation and transformation. DataFlowMapper's validation engine can instantly flag all records where the data type is incorrect. Then, using the visual Logic Builder, you can create a conditional transformation (e.g., IF source_field == 'Yes' THEN return TRUE, ELSE return FALSE) to automatically standardize the data to the correct type across the entire dataset.
Try DataFlowMapper risk-free for 30 days.
The cost of manual data cleaning, in time, money, and morale, is a strategic liability. Most data import failures stem from a fundamental mismatch: the forgiving, dynamic nature of spreadsheets versus the rigid, structured requirements of databases and applications. The solution is not better spreadsheets; it's a better system.
A resilient, automated data onboarding process is built on three pillars:
By moving beyond manual workarounds and spreadsheet gymnastics, you can eliminate the hidden costs of bad data, free your team from being "data janitors," and build a data pipeline you can finally trust.
Why does Excel corrupt my CSV files by removing leading zeros? Excel's default 'General' format automatically interprets columns containing numbers as mathematical values, not text identifiers. This causes it to truncate leading zeros (e.g., in ZIP codes) and convert long numbers to scientific notation. The best solution is to use a data tool that allows you to define column types as 'Text' before opening the file, preserving data integrity.
What is the most common reason for data being shifted into the wrong columns? This is almost always caused by unescaped commas or quotes within your data. If a field contains a comma (like 'City, State'), it must be enclosed in double quotes. A robust CSV parser or data transformation tool can handle this automatically, but it's a primary failure point for simple scripts or import wizards.
How can I fix date format issues when importing data from different regions? Manually fixing dates with formulas is slow and error-prone. The most reliable method is to use a data transformation tool with a dedicated date parsing function. This allows you to specify the incoming format (e.g., 'DD/MM/YYYY') and standardize it to a universal format like 'YYYY-MM-DD' across the entire dataset in one step.
Our import files are often huge (millions of rows) and crash Excel. How can we handle them? Spreadsheets like Excel load the entire file into memory, which is why they crash with large datasets. Modern data transformation platforms like DataFlowMapper use a streaming architecture to process files chunk-by-chunk. This allows them to handle massive datasets efficiently without memory limitations, eliminating the need to manually split files.
Can't I just write a Python script to handle all these issues? While you can, scripting creates dependencies on developers, is hard to maintain, and lacks a user interface for business users to validate or manage rules. A dedicated platform provides the power of code within a visual, collaborative, and reusable framework, drastically reducing developer bottlenecks and making the process accessible to the entire implementation team.
[1] Gartner. (2025). What Is Data Quality? IBM.
[2] Pragmatic Institute. (2025). Overcoming the 80/20 Rule in Data Science.
[3] Yashvaant. (2025). Why Your Data Cleaning Takes 70% of Your Time. Medium.
[4] Reddit user comment on r/excel. (2025). "Excel doesn't allow me to see leading zeros".
[5] Super User. (2025). "Why does Excel treat long numeric strings as scientific notation even after changing cell format to text".
[6] CIMcloud Help Center. (2025). "Order Import Error: Zipcode Not on File".
[7] OneSchema. (2025). 6 Reasons your customers are facing CSV import issues.
[8] Stack Overflow. (2025). "Parsing a CSV file and having trouble parsing the date".
[9] Reddit user comment on r/Notion. (2025). "basic date problem when importing .csv data".
[10] Amit Yadav. (2025). How to Read CSV Files with Parsed Dates in Pandas? Medium.
[11] Reddit user comment on r/excel. (2025). "I tried everything to solve the date format but failed.".
[12] Row Zero. (2025). 10 Common CSV Errors and Fundamental CSV Limits.
[13] Stack Overflow. (2025). "Import CSV File Error : Column Value containing column delimiter".
[14] YouTube. (2025). "Escaping Commas in CSV Data".
[15] Flatfile. (2025). The top 6 Excel data import errors and how to fix them.
[16] Reddit user comment on r/Anki. (2025). "How I resolved the UTF-8 format error issue when importing CSV files".
[17] hcibib.org. (2025). When Good Characters Go Bad: A Guide to Diagnosing Character Display Problems.
[18] MotionPoint. (2025). Character Encoding and Its Importance for Translated Websites.
[19] Microsoft Learn. (2025). "How to fix error 'Could not find a delimiter after string delimiter' with External table on Synapse?".
[20] Online surveys. (2025). Common problems when importing or exporting respondents ADVANCED.
[21] Microsoft Support. (2025). Import or export text (.txt or .csv) files.
[22] Reddit user comment on r/Rlanguage. (2025). "Tips and tools for cleaning a CSV with inconsistently quoted string variables?".
[23] GitHub. (2025). "NULL value imported from CSV file become empty string · Issue #195".
[24] Kaggle. (2025). Missing Values.
[25] Reddit user comment on r/excel. (2025). "Anyone else feel like they spend more time formatting than actually...".
[26] Integrate.io. (2025). Excel Import Errors? Here's How to Fix Them Fast.
[27] Corporate Finance Institute. (2025). Excel Convert Formula to Value.
[28] Microsoft Tech Community. (2025). "Invalid CSV format - number of col in rows do not match number of columns in headers-missing commas?".
[29] The eBay Community. (2025). "Uploading CSV fails - we couldn't identify your template".
[30] Reddit user comment on r/learnpython. (2025). "strange encoding error with csv?".
[31] Reddit user comment on r/excel. (2025). "Removing Trailing Spaces from Imported Data".
[32] Ingestro. (2025). 5 CSV File Import Errors (and How to Fix Them Quickly with Ingestro).
[33] Microsoft Support. (2025). Convert numbers stored as text to numbers in Excel.
Excel's default 'General' format automatically interprets columns containing numbers as mathematical values, not text identifiers. This causes it to truncate leading zeros (e.g., in ZIP codes) and convert long numbers to scientific notation. The best solution is to use a data tool that allows you to define column types as 'Text' *before* opening the file, preserving data integrity.
This is almost always caused by unescaped commas or quotes within your data. If a field contains a comma (like 'City, State'), it must be enclosed in double quotes. A robust CSV parser or data transformation tool can handle this automatically, but it's a primary failure point for simple scripts or import wizards.
Manually fixing dates with formulas is slow and error-prone. The most reliable method is to use a data transformation tool with a dedicated date parsing function. This allows you to specify the incoming format (e.g., 'DD/MM/YYYY') and standardize it to a universal format like 'YYYY-MM-DD' across the entire dataset in one step.
Spreadsheets like Excel load the entire file into memory, which is why they crash with large datasets. Modern data transformation platforms like DataFlowMapper use a streaming architecture to process files chunk-by-chunk. This allows them to handle massive datasets efficiently without memory limitations, eliminating the need to manually split files.
While you can, scripting creates dependencies on developers, is hard to maintain, and lacks a user interface for business users to validate or manage rules. A dedicated platform provides the power of code within a visual, collaborative, and reusable framework, drastically reducing developer bottlenecks and making the process accessible to the entire implementation team.