Beyond Checkboxes: Mastering Data Validation for Seamless Customer Onboarding
Customer onboarding: it's the critical first handshake between your software and your client's reality. Get it right, and you pave the way for rapid adoption, trust, and long-term success. Get it wrong – especially when wrangling data from ubiquitous CSV and Excel files – and you risk operational chaos, frustrated users, delayed revenue, and eroded confidence.
While basic data validation guides might cover checking if a field contains a number or if an email looks like an email, that's merely scratching the surface. For implementation specialists, data migration teams, and onboarding analysts navigating the complexities of real-world customer data, true mastery demands going far beyond simple checkboxes. It means confronting intricate business rules, overcoming the inherent limitations of spreadsheets, and leveraging modern techniques – including AI – to ensure data isn't just present, but correct, consistent, and meaningful within the context of your system.
If you're wrestling with data that looks "valid" but breaks processes downstream, or if the cycle of manual error correction in spreadsheets is crippling your onboarding timelines, this guide is for you. Understanding how to handle data validation in software effectively, especially when dealing with flexible formats and complex business requirements, is crucial for smooth implementations. We'll dive deep into how to validate data and advanced data validation strategies tailored for customer onboarding involving CSV, Excel, and JSON data, exploring:
- The Spreadsheet Trap: Why standard validation falls short with flexible formats.
- Business Rule Validation: The non-negotiable layer for data integrity.
- Advanced Techniques: Expanding your validation toolkit beyond the basics.
- Escaping the Re-processing Nightmare: Building efficient error handling and remediation workflows.
- AI as a Validation Co-Pilot: How artificial intelligence is enhancing the process.
- Strategic Best Practices: Building a resilient and scalable validation framework.
The Spreadsheet Trap: Why Standard Validation Isn't Enough
CSV and Excel are the lingua franca of data exchange – simple, accessible, and universally understood. But this very flexibility is their Achilles' heel during data onboarding:
- Schema? What Schema? Unlike databases, spreadsheets don't enforce strict data types. Text invades numeric fields ("100 units" instead of 100), dates become a chaotic mix (MM/DD/YY, YYYY-MM-DD, DD-Mon-YYYY), and crucial leading zeros vanish from identifiers like ZIP codes or product SKUs. Consistency is often the first casualty.
- Formatting Roulette: Beyond dates, inconsistent decimal separators, currency symbols, or text casing ("New York" vs. "new york") create integration headaches. Commas within data fields can sabotage CSV parsing, shifting columns unexpectedly. Character encoding mismatches can garble essential information.
- The Void of Missing Data: How is "missing" data represented? An empty cell? "NULL"? "N/A"? "#VALUE!"? This ambiguity requires explicit handling during validation.
- Lost in Translation: Critical business logic embedded in Excel formulas or manual processes evaporates when exported to flat CSV files, leaving you with raw values stripped of their original context.
Relying only on basic format or type checks in this environment is like checking if puzzle pieces are square without seeing if they form the correct picture. The data might pass superficial checks but remain functionally useless or even harmful once loaded.
Beyond Format Checks: Why Business Rule Validation is Non-Negotiable
The most critical gap in basic validation is its inability to verify data against your specific business logic. Your system doesn't just need a date; it needs an order date that occurs after the account activation date. It doesn't just need a transaction code; it needs a code that's valid for that specific client's service tier and geographic region.
This is where Business Rule Validation comes in. It ensures data makes sense within the operational context of your software. Examples are numerous and vital:
- Cross-Field Consistency: Is the 'Shipping State' ("CA") consistent with the 'Shipping Zip Code' prefix ("90210")? Does the 'Invoice Total' correctly reflect 'SUM(LineItemTotals) + Tax - Discount'?
- Conditional Requirements: Is a 'Cancellation Reason Code' provided only if the 'Subscription Status' is "Cancelled"? Is 'Manager Approval' required if 'Discount Percentage' exceeds 15%?
- Relational Integrity (Implicit & Explicit): Does the 'ProductID' listed in an order file actually exist in the master product list? Does the 'SalespersonID' belong to someone in the active sales team roster?
- Complex Calculations & Logic: Validating intricate financial calculations involving tiered pricing, currency conversions, or specific rounding rules. Ensuring source transaction types (e.g., "ACH Deposit - Payroll") correctly map to target system categories based on multiple criteria like amount and description keywords.
- Regulatory & Compliance Checks: Does the data adhere to industry-specific formats or constraints (e.g., HIPAA compliance rules for healthcare data, transaction limits in finance)?
Ignoring business rule validation means allowing functionally incorrect data into your system, leading to flawed reports, broken workflows, compliance failures, and ultimately, a poor customer experience.
Expanding the Toolkit: Advanced Data Validation Techniques
A robust strategy layers multiple validation techniques. While foundational checks are necessary, advanced methods tackle the deeper complexities:
Foundation Checks (The Basics):
- Data Type: Integer, String, Date, Boolean, etc.
- Format: Email syntax, phone patterns (e.g., E.164), date formats (ISO 8601 preferred), specific code structures (using Regular Expressions).
- Range: Numerical/date boundaries (0-100%, positive values only, date not in the future).
- Uniqueness: No duplicates for key identifiers (Customer ID, Order Number, Email).
- Presence (Completeness): Mandatory fields are not null/empty.
Advanced Techniques (Essential for Complex Onboarding):
- Referential Integrity & Lookups: Crucial for ensuring relationships between data points are valid. This often goes beyond checking within the uploaded file itself.
- Challenge: How do you validate a 'CustomerID' in an uploaded 'Orders.csv' against your live customer database?
- Modern Solution: Employing remote lookups during validation. This involves querying external data sources (databases via SQL, APIs, other validated files) as part of the validation rule. For example: "Validate 'Orders.CustomerID' by checking if it exists in the result of 'SELECT id FROM customers WHERE id = [CustomerID]'". Tools facilitating these lookups directly within the validation logic are essential for maintaining consistency with master data.
- Complex Business Logic Implementation: Moving beyond simple checks to encode multi-step, conditional rules.
- Implementation: Requires flexible solutions:
- Visual Logic Builders: Empowering analysts to graphically construct rules by dragging-and-dropping fields, functions (IF/THEN/ELSE, LOOKUP, CALCULATE), and logical operators, often without writing code.
- Scripting/Code: Providing the power of languages like Python for highly specific, intricate, or proprietary validation logic that visual builders might not accommodate. Example Python snippet (conceptual):
def validate_order_discount(record):
if record['ClientTier'] == 'Premium' and record['OrderValue'] > 5000:
if record['DiscountPercentage'] > 0.20:
return False, "Premium clients max discount is 20% on orders over $5000"
# ... other checks ...
return True, ""
- Statistical Validation: Using statistical analysis to spot anomalies that might pass rule-based checks. Identifying outliers (e.g., an order quantity vastly larger than average) or unexpected distributions can flag potential errors or fraud.
Layering these techniques provides a comprehensive defense against the diverse data quality issues encountered during onboarding and can serve as fundamental rules of data validation.
Escape the Excel Loop: Building Efficient Remediation Workflows
Finding errors is only half the battle. How you handle them determines whether onboarding is smooth or a nightmare. The traditional "find errors -> manually edit Excel -> re-upload -> re-validate" cycle is notoriously inefficient and error-prone.
The Manual Re-processing Nightmare: Imagine finding 100 validation errors scattered across a 50,000-row spreadsheet. Correcting these manually in Excel is tedious, risks introducing new errors (typos, accidentally changing other cells), lacks an audit trail, and offers no guarantee the same mistake won't happen on the next upload. It's a major bottleneck.
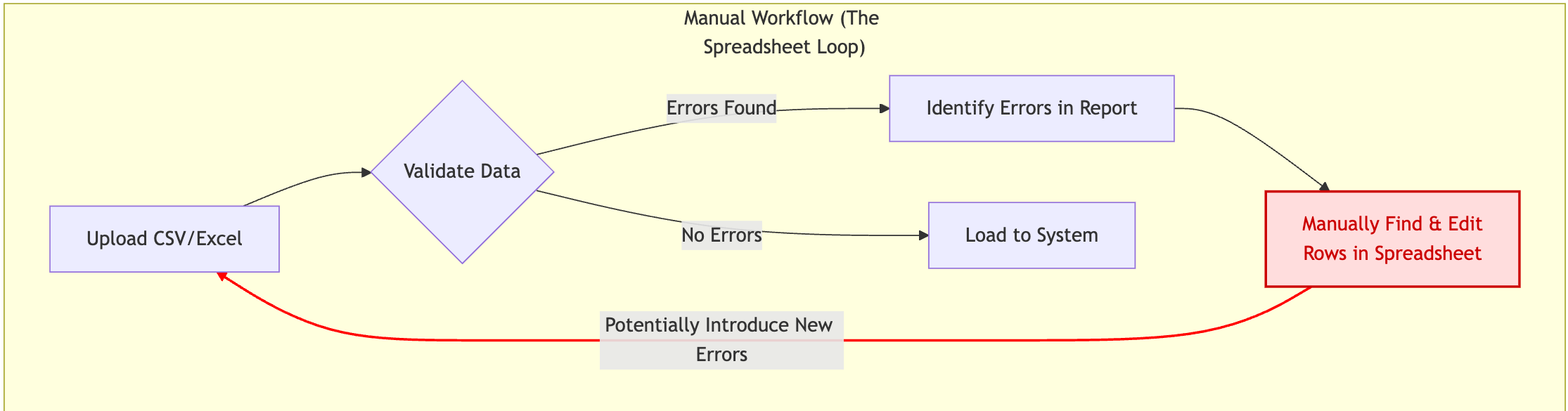
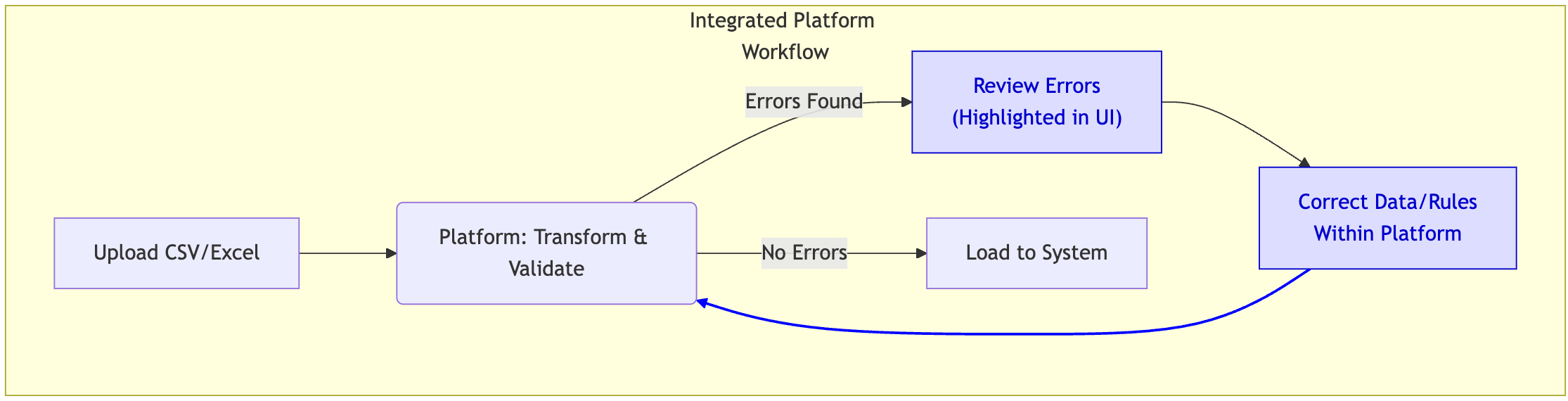
A Better Way: Integrated Remediation & Re-processing:
- Clear, Actionable Error Feedback: Validation failures must be presented clearly:
- Identification: Highlight the specific rows and cells containing errors.
- Explanation: Provide user-friendly messages explaining which rule failed and why (e.g., "Invalid State Code 'XX'. Expected 2-letter US state abbreviation.", "Order Date cannot be before Customer Creation Date.").
- Context: Show the problematic data alongside expected formats or valid values where applicable.
- Efficient Correction Mechanisms: Offer ways to fix data without resorting to manual spreadsheet edits:
- In-App Editing: Allow direct correction within a staging grid interface where errors are displayed.
- Rule Adjustment: Enable modification of the underlying transformation or mapping rules that caused the error.
- Guided Source Correction: Provide clear instructions if the fix must happen in the original source system.
- Seamless, Repeatable Re-processing: This is paramount. Once corrections are made (to data or rules), the system must allow easy re-validation ofs the affected records through the exact same transformation and validation pipeline. This ensures consistency, leverages the defined logic, and avoids the pitfalls of manual intervention. Modern data onboarding platforms often integrate transformation, validation, and remediation into a single, repeatable workflow.
AI as a Validation Co-Pilot: Smarter, Faster Onboarding
Artificial Intelligence is emerging as a powerful ally, augmenting human expertise to make data validation more intelligent and efficient.
- AI-Powered Mapping & Rule Suggestion: AI analyzes source/target schemas and data patterns to propose initial field mappings and potential validation rules (e.g., identifying likely unique keys, suggesting range checks based on data distribution, recognizing common patterns like email addresses).
- Natural Language to Validation Logic: Users can describe requirements in plain English (e.g., "Ensure the delivery zip code matches the state"), and AI can translate this into formal validation rules or code snippets compatible with the validation engine. This significantly lowers the barrier to creating complex rules.
- Intelligent Anomaly Detection: AI algorithms excel at finding subtle outliers or inconsistent patterns across large datasets that might be missed by explicit, pre-defined rules, flagging records for human review.
- Automated Data Classification: AI can help automatically categorize fields (e.g., identifying PII, classifying address components), which informs the application of relevant validation standards.
It's also important to recognize that AI's role often starts even before validation. Sophisticated AI data mapping capabilities in modern platforms can analyze source fields, target schemas, and data values to automatically suggest or perform initial field mappings and even analyze data for anomalies, dramatically accelerating the setup phase before validation rules are even applied.
Crucial Context: AI is a co-pilot, not the pilot. Human oversight remains essential to review AI suggestions, confirm their business relevance, handle nuanced exceptions, and ensure alignment with specific organizational policies. The goal is AI-assisted validation, leveraging its power to accelerate tasks traditionally done by experts.
Blueprint for Resilience: Best Practices for a Robust Validation Strategy
Building a reliable data validation framework isn't a one-off task; it's a strategic commitment. The following data validation best practices outline the core elements of an effective data validation process and the key steps to ensure data quality during onboarding and data migration:
- Define Requirements Rigorously: Collaborate closely with business stakeholders, subject matter experts, and customers before onboarding starts. Document data definitions, quality thresholds, critical business rules, and acceptance criteria.
- Profile Data Early & Often: Analyze sample customer data upfront to understand its nuances, anticipate common quality pitfalls (like inconsistent date formats or missing values), and tailor validation rules accordingly. Validate and verify data quality at every stage of the data conversion process to catch issues and avoid surprises.
- Choose Tools Wisely: Select appropriate data onboarding tools or data validation platforms that match your complexity. Simple format checks might use basic scripts or built-in spreadsheet features (used cautiously!), but handling complex business rules, external lookups, and efficient remediation demands dedicated data onboarding tools or platforms offering visual logic builders, scripting capabilities, API integration, and integrated transformation/validation/remediation workflows. Avoid relying solely on Excel's limited validation for critical onboarding processes.
- Automate Relentlessly: Automate rule execution, error reporting, and especially the re-processing workflow. Manual steps introduce delays, inconsistencies, and errors.
- Prioritize Impact: Focus validation efforts on the rules safeguarding critical business processes, data integrity, compliance, and customer experience. Not all rules carry equal weight.
- Document Everything: Maintain a clear, accessible repository for all validation rules (purpose, logic, fields), procedures (tools, steps, responsibilities), and error handling protocols. This ensures consistency, aids troubleshooting, supports audits, and facilitates training.
- Iterate and Refine: Treat your validation framework as a living entity. Monitor its effectiveness, collect feedback from onboarding teams and customers, analyze error patterns, and continuously improve rules and workflows.
- Design for Remediation: Build the error handling and re-processing workflow with user experience and efficiency as top priorities. How easily can users understand errors? How quickly and reliably can they fix them and re-validate?
Conclusion: Elevate Data Onboarding from Chore to Competitive Advantage
Mastering data validation is fundamental to successful data onboarding, especially when dealing with challenging formats like CSV and Excel. Having a framework and data validation plan is far more than a technical necessity – it's a strategic advantage. It requires moving beyond superficial checks to embrace the complexities of business logic, leveraging advanced techniques like remote lookups, and designing efficient, repeatable workflows for error remediation.
By strategically incorporating automation and AI assistance, organizations can transform this critical process. Investing in a robust, intelligent data validation framework minimizes costly errors, accelerates customer time-to-value, reduces operational friction, builds foundational trust, and ultimately turns onboarding from a potential minefield into a smooth pathway for long-term customer success.
