
Escape VLOOKUP Hell: Modern Alternative for ID Mapping
Introduction: The Universal Agony of Reference ID Mapping
If you've ever spent hours wrestling with 'VLOOKUP' formulas, trying to map external customer IDs to your internal system's 'ReferenceID', or linking product codes from a supplier's CSV file to your master product database, you know the pain. Reference ID mapping is a critical step in almost every data import, migration, or onboarding project. It's the process of connecting data from one system to another using common identifiers.
But let's be honest: for many, this process is synonymous with "VLOOKUP hell." It's often a time-consuming, error-prone nightmare, plagued by '#N/A' errors, performance slowdowns with large datasets, and the sheer tedium of managing multiple lookup tables. The truth is, traditional spreadsheet methods are increasingly falling short for the complex data import needs of modern businesses. It's time for a better way.
Why VLOOKUPs (and Basic Scripts) Are Holding You Back
For years, 'VLOOKUP' in Excel or Google Sheets has been the go-to for many. While seemingly simple for basic tasks, its limitations become glaringly obvious as data complexity and volume grow.
Deep Dive into VLOOKUP Limitations:
- Performance Bottlenecks: With tens of thousands of rows, 'VLOOKUP's can grind your spreadsheet to a halt.
- Rigidity: The lookup column must be the first column in your lookup table, often forcing awkward data restructuring or copy & pasting. Exact matches can be finicky, and approximate matches are often not what's needed.
- Error Handling Complexities: Wrapping every 'VLOOKUP' in 'IFERROR' (or 'IFNA') to handle missing values creates bloated, hard-to-read formulas.
- Scalability & Maintainability: Managing lookups across multiple sheets or files, or dealing with slightly different lookup criteria, quickly becomes a maintenance nightmare. Trying to prevent Excel from changing data types or losing leading zeros adds another layer of frustration.
- File Size & Row Limits: Excel has its limits, and pushing them with massive lookup tables isn't a sustainable strategy.
Challenges with Basic Scripting (e.g., ad-hoc Python):
While Python with Pandas offers more power, relying on ad-hoc scripts for every lookup task isn't always the answer:
- Requires Coding Expertise: This creates a bottleneck if your implementation specialists or data analysts aren't proficient coders.
- Time-to-Develop: Even for "simple" lookups, writing, testing, and debugging scripts takes time that could be better spent.
- Maintenance Overhead: Scripts can become "knowledge silos," difficult for others to understand or modify if the original author leaves.
- Less Accessible: Non-technical team members can't easily review, modify, or troubleshoot script-based logic. Managing dependencies or environment setup for scripts across a team isn't always feasible.
It's clear that a more robust, efficient, and accessible approach is needed.
The Modern Playbook: Key Strategies for Robust ID Mapping
To truly escape "VLOOKUP hell" and streamline your reference ID mapping, consider these modern strategies:
- Centralize & Standardize Lookup Data: Ensure your reference tables are clean, accurate, and consistently formatted creating a single source of truth for your reference datasets.
- Leverage Dedicated, Powerful Lookup Capabilities: Move beyond simple joins to tools designed for complex lookup scenarios.
- Embrace Visual Mapping for Clarity & Speed: Visually defining how source data connects to lookup tables and then to target fields dramatically simplifies the process.
- Build for Repeatability & Scalability: Your lookup logic should be easy to save, reuse, and apply to large datasets without performance degradation.
Putting Theory into Practice: Mastering ID Mapping with DataFlowMapper
DataFlowMapper is designed to embody these modern strategies, offering powerful and intuitive ways to handle even the most complex reference ID mapping challenges. Instead of fighting with formulas or writing one-off scripts, you can visually configure, test, and reuse your lookup logic.
Let's look at how DataFlowMapper tackles common ID mapping scenarios:
Scenario A: 'LocalLookup' – Your Self-Contained Reference Library
Often, you have static reference tables (e.g., a list of country codes, product categories, or internal department IDs) that you need to look up against. DataFlowMapper's 'LocalLookup' function is perfect for this. You can upload these lookup tables (as CSV, Excel, or JSON files) directly into your mapping configuration to efficiently join datasets.
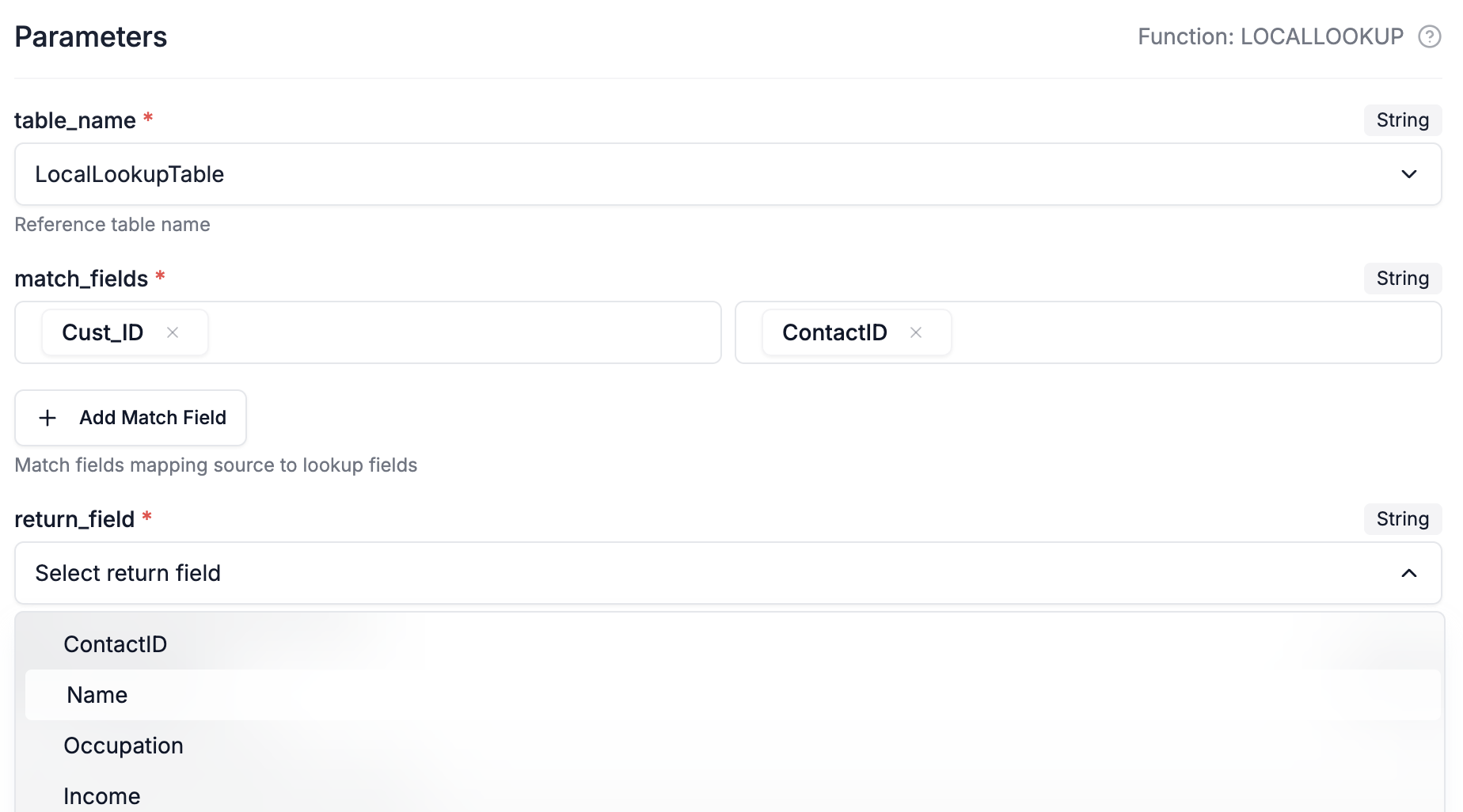
How it works: The 'LocalLookup' function allows you to specify:
- The name of your uploaded lookup table.
- The fields to match between your source data and the lookup table to serve as keys.
- The field from the lookup table whose value you want to return.
- Whether to return all matches (as a list) or just the first/last one.
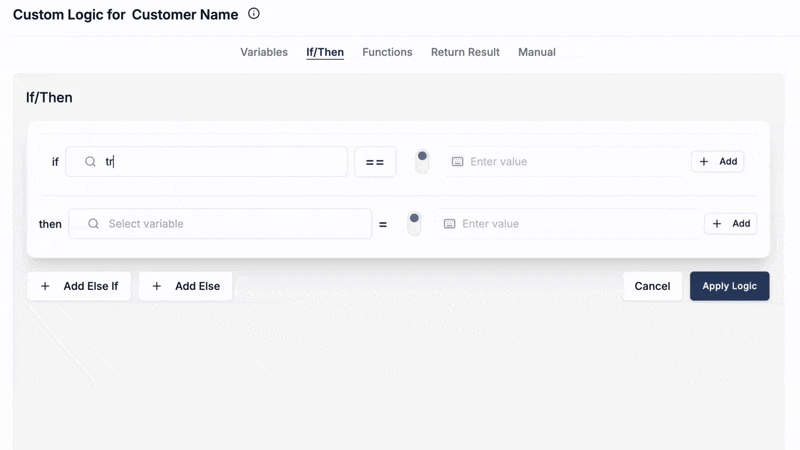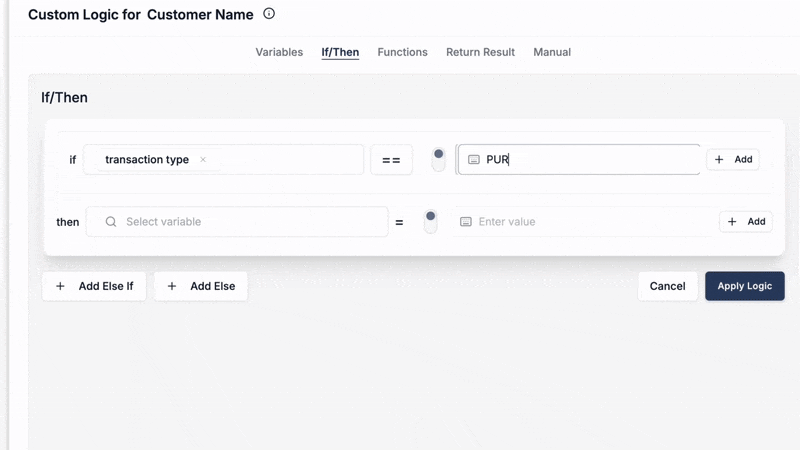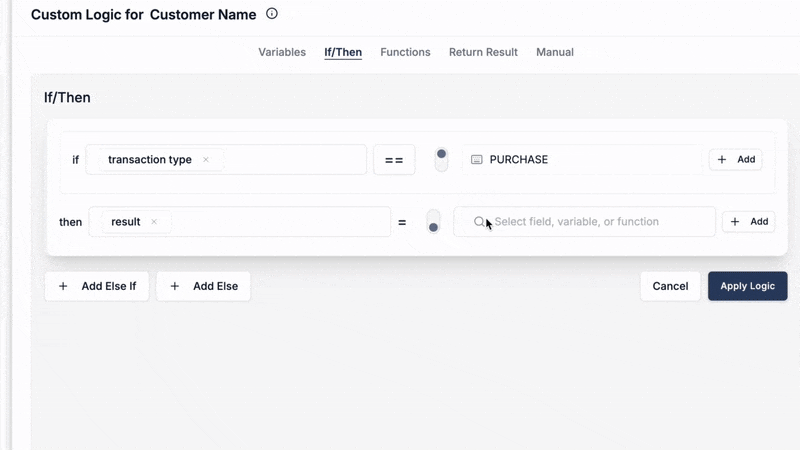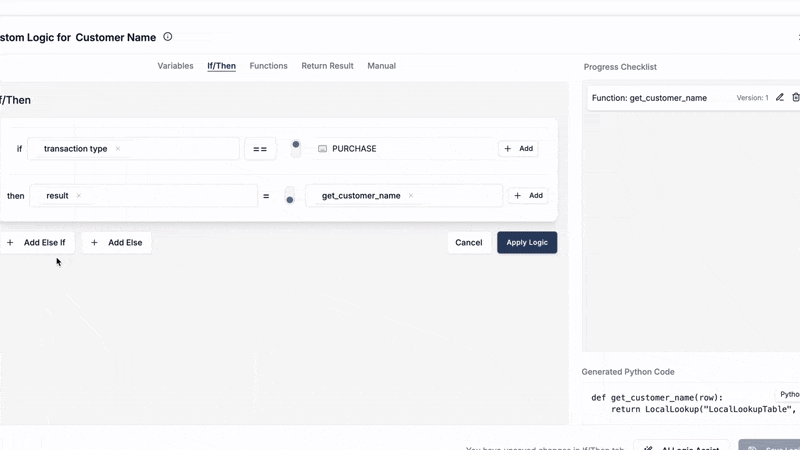
Example in DataFlowMapper's Logic Builder: Imagine you have a source CSV with a 'Cust_ID' and you want to look up the customer's 'Name' from an uploaded table called 'LocalLookupTable' where 'Cust_ID' in your source matches 'ContactID' in the lookup table.
In DataFlowMapper's visual Logic Builder, you could configure this, or if using the Python mode within the builder, the generated code might look like this (Using visual logic builder will generate this code automatically).:
# Define a reusable lookup operation
def get_customer_name(row):
# Parameters:
# 1. 'LocalLookupTable': Name of the uploaded lookup file.
# 2. [{'source': row['Cust_ID'], 'table': 'ContactID'}]:
# Match where 'Cust_ID' from the current input row
# equals 'ContactID' in the 'LocalLookupTable'.
# 3. 'Name': The column to return from 'LocalLookupTable'.
# 4. False: Return only the first match (not all matches).
return LocalLookup('LocalLookupTable', [{'source': row['Cust_ID'], 'table': 'ContactID'}], 'Name', False)
# In your field mapping, you'd then use:
# mapped_customer_name = get_customer_name(row)
Benefits:
- Encapsulated Logic: The lookup table and logic are part of your saved mapping. Self-contained and shareable.
- Speed: Lookups are performed efficiently in memory. Handling complex join conditions visually significantly reduces overhead of scripting or writing multiple formulas.
- No External Dependencies: Doesn't rely on external databases or APIs at runtime for these static lookups.
Scenario B: 'RemoteLookup' – Connecting to Live Data (APIs/Databases)
What if your reference data lives in an external database or is accessible via an API (e.g., looking up the latest product price or checking if a customer ID exists in your live CRM)? DataFlowMapper's 'RemoteLookup' function handles this.
How it works: You configure connections to your APIs or databases within DataFlowMapper. Then, 'RemoteLookup' allows you to:
- Specify the source type ('api' or 'db') and the pre-configured source ID.
- Define the fields to match between your input data and the remote source.
- Specify the field to return from the remote source.
- Optionally, retrieve all matches.
DataFlowMapper intelligently caches data from 'RemoteLookup' calls during a transformation run to optimize performance and avoid repeatedly hitting external systems.
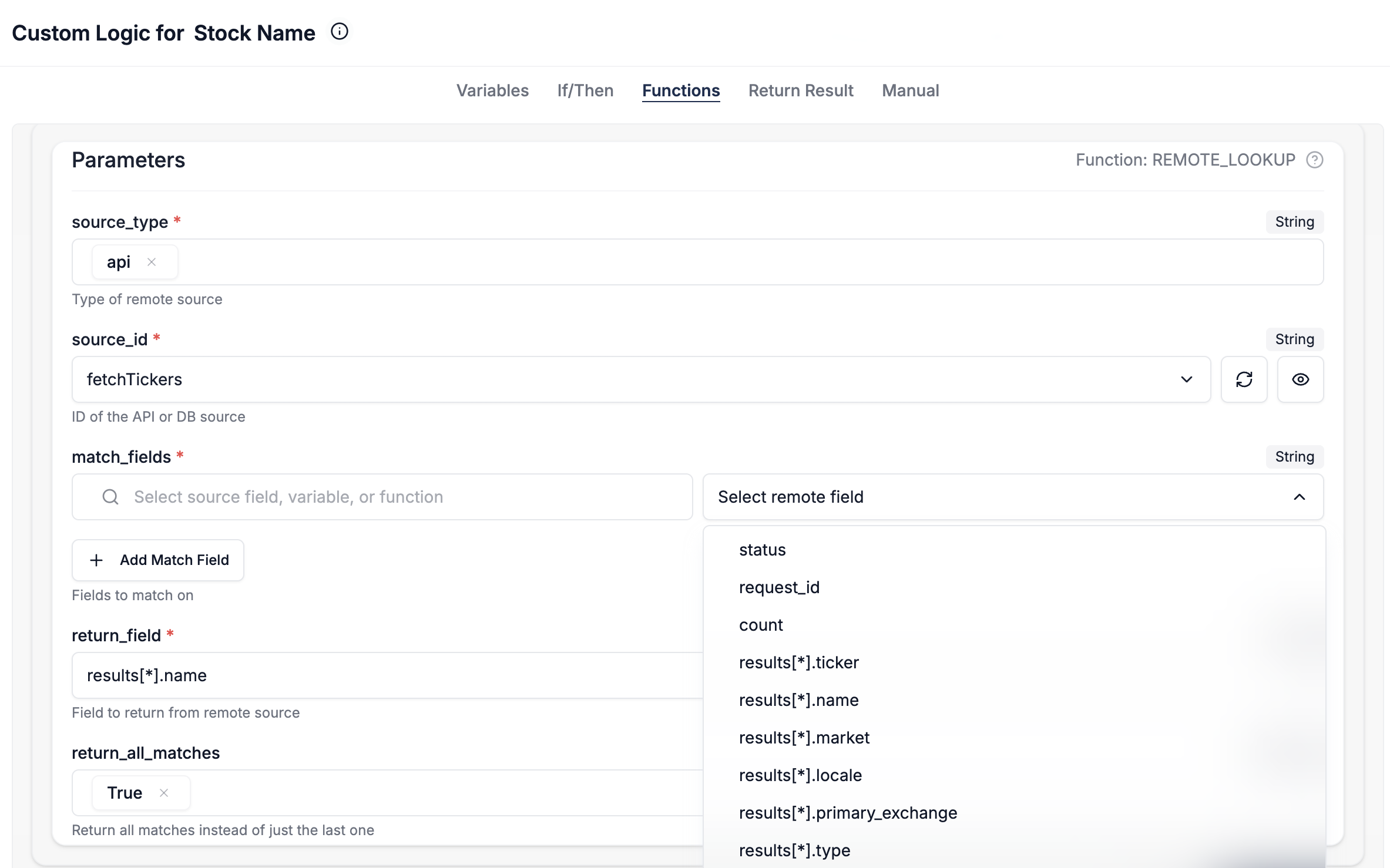
Example (Conceptual): To look up an 'AccountManager' from a Salesforce API based on an 'OpportunityID' from your source file:
# Conceptual Python-like usage in DataFlowMapper's Logic Builder
def get_account_manager(row):
# Parameters:
# 1. "api": Type of the remote source.
# 2. "salesforce_api_connection": Name/ID of your configured API connection.
# 3. [{'source': row['OpportunityID'], 'remote': 'OpportunityId_ApiField'}]:
# Match where 'OpportunityID' from the input row
# equals 'OpportunityId_ApiField' in the API response.
# 4. "AccountManager_ApiField": The field to return from the API.
# 5. False: Return only the first match.
return RemoteLookup("api", "salesforce_api_connection", [{'source': row['OpportunityID'], 'remote': 'OpportunityId_ApiField'}], "AccountManager_ApiField", False)
# Usage:
# mapped_manager = get_account_manager(row)
Benefits:
- Always Up-to-Date: Fetches the latest data from your live systems.
- Handles Dynamic Data: Ideal for reference data that changes frequently.
- Reduces Data Silos: Directly integrates with your existing data sources.
- Real-Time Data Quality: With real-time access to the destination system, you can perform real-time validation or duplication checks.
Scenario C: Advanced Conditional Lookups with the Logic Builder
Sometimes, your lookup logic isn't straightforward. You might need to:
- Choose between different lookup tables based on a source field's value.
- Perform a lookup only if certain conditions are met.
- Clean or transform a source key before using it in a lookup.
DataFlowMapper's Logic Builder provides a powerful visual interface (and an integrated Python editor for advanced users) to construct such complex conditional logic around your lookups. You can combine 'LocalLookup' or 'RemoteLookup' with 'IF/THEN/ELSE' blocks, variables, and over 50 other built-in functions.
Key DataFlowMapper Advantages for ID Mapping:
- Intuitive Visual Interface: Simplifies configuring and understanding lookups.
- Support for Multiple Match Keys: Join on composite keys with ease.
- Robust Error Handling: Clearly see which lookups failed and why, aiding in data validation and quality control.
- Reusable Configurations: Save your entire mapping, including all lookup definitions, and reuse it for future imports.
- Scalability: Designed to handle large datasets efficiently.
When considering ETL vs. Import Tools vs. Advanced Platforms, DataFlowMapper provides the advanced capabilities needed for these critical transformation tasks without the overhead of traditional enterprise ETL.
The Transformation: Benefits of Modernizing Your ID Mapping
Moving beyond 'VLOOKUP's and ad-hoc scripts to a dedicated solution like DataFlowMapper for reference ID mapping offers significant advantages:
- Massive Time Savings: Automate what used to take hours of manual formula writing or scripting.
- Dramatically Improved Data Accuracy: Reduce human error and ensure consistent application of lookup logic, leading to fewer import rejections.
- Increased Team Productivity: Empower both technical and less-technical team members to handle complex data preparations.
- Better Scalability: Confidently process large and growing datasets without performance anxiety.
- Enhanced Auditability & Troubleshooting: Clearly trace how data was transformed and quickly identify the source of any lookup issues.
Conclusion: Make "VLOOKUP Hell" a Relic of the Past
The days of battling cryptic spreadsheet formulas or writing endless variations of lookup scripts are over. By adopting a modern playbook for reference ID mapping, centered around powerful, visual, and repeatable tools, you can transform this once-dreaded task into a streamlined and efficient part of your data import workflow.
Stop letting 'VLOOKUP' limitations dictate your data preparation timelines and accuracy. It's time to take control.
FAQs:
-
Q: How is DataFlowMapper's 'LocalLookup' different from just using VLOOKUP or INDEX/MATCH in Excel? A: While VLOOKUP/INDEXMATCH work within Excel, DataFlowMapper's 'LocalLookup' integrates lookup tables (CSV, Excel, JSON) directly into a repeatable, shareable mapping configuration. This means your logic is self-contained, versionable, and not tied to a specific spreadsheet's structure. It also handles larger datasets more efficiently and provides clearer error handling within a dedicated data transformation environment, avoiding common Excel pitfalls like performance degradation or data integrity issues.
-
Q: Can DataFlowMapper's lookups handle matching on multiple columns (composite keys)? A: Yes! Both 'LocalLookup' and 'RemoteLookup' in DataFlowMapper allow you to define multiple match conditions. You can easily specify several pairs of source fields and lookup table fields that must all match for a successful lookup, a task that is often cumbersome with standard spreadsheet functions.
-
Q: What if my reference data isn't in a static file but in a live database or API that changes frequently? A: That's precisely what DataFlowMapper's 'RemoteLookup' function is designed for. You can configure connections to your databases (like PostgreSQL, MySQL, SQL Server) or various APIs. 'RemoteLookup' then queries these live sources during your transformation, ensuring you're always using the most up-to-date reference data for your ID mapping. The system also intelligently caches data during a run to optimize performance.
-
Q: How does DataFlowMapper help if a lookup doesn't find a match for a particular record? A: DataFlowMapper provides robust ways to handle non-matches. Within the Logic Builder, you can use conditional logic (IF/THEN/ELSE) to define fallback values, assign a specific status, or even trigger different actions if a lookup fails. This gives you full control over data quality and exception handling, rather than just getting a standard error.
-
Q: Is it complicated to set up these advanced lookups in DataFlowMapper if I'm not a Python expert? A: Not at all. While DataFlowMapper offers a full Python IDE for ultimate flexibility, its core Logic Builder is designed for no-code users. You can configure 'LocalLookup' and 'RemoteLookup' through a visual interface—selecting your tables/sources, choosing match fields from dropdowns, and specifying return values, all without writing code. The Python is generated for you but you don't need to interact with it unless you want to.
Ready to see how DataFlowMapper can revolutionize your reference ID mapping and other data transformation challenges? Sign up or schedule a walkthrough by clicking below.
Escape VLOOKUP Hell for Good
Stop wrestling with complex lookups. See how DataFlowMapper makes ID mapping fast, accurate, and repeatable.